[V8 Deep Dives] Javascript Map을 파헤쳐보자
본 글은 Andrey Pechkurov의 Understanding Map Internals를 원작자의 허가를 받아 번역한 글입니다.
Iterable은 순서체, Iterator는 반복자, Iteration은 순차 실행으로 번역하였습니다.

이번 포스트는 V8 Deep Dive 시리즈의 첫번째 포스트다. V8 Deep Dive시리즈에서는 V8 엔진에 대해서 직접 경험하고 찾은 내용들을 자세하게 전달할 예정이다. 이 포스트가 V8 엔진에 대한 이해에 도움이 되기를 빈다. 다음 주제에 대한 좋은 아이디어가 있으면 감사히 받겠다.
시작
ECMAScript 2015(ES6)는 Map, Set, WeakMap, 그리고 WeakSet 등의 다양한 자료구조를 내장하고 있다. 이는 표준 JS 라이브러리 및 다른 라이브러리, 어플리케이션, Node.js 코어까지 적용되었다. 이번 글에서는 Map 자료구조에 대한 V8에서의 구현 방법과 실용적으로 쓰려면 뭐가 필요한지 살펴보자.
ES6 명세에는 Map을 구현하기 위한 알고리즘을 강제하고 있지 않지만, 대신 구현의 조건과 성능상의 특징이 기술되어있다.
Map 객체는 해시 테이블 또는 저장된 데이터의 수에 따라 선형적으로 접근 시간이 증가하는 다른 알고리즘을 이용하여 구현되어야 합니다. 이 명세에 기술된 자료구조는 Map 객체 구현에 요구되는 시맨틱 구조를 설명하기 위한 것으로, 실행 가능한 구현체가 아닙니다.
명세에서 살펴볼 수 있듯 다양한 구현 방법에 대해 여지를 남겨두면서 알고리즘, 성능 또는 구현에 대해 자세하게는 설명하지 않는다. 알고리즘, 성능, 구현에 대한 자세한 내용들은 많은 데이터를 Map에 저장할 때 많은 도움이 될 수 있다.
내가 Java로 개발할 때, Java collection은 다양한 Map 인터페이스의 여러 구현체 중 하나를 선택하고 필요하면 직접 튜닝도 할 수 있었다. 그리고 Java는 표준 라이브러리의 모든 클래스가 오픈소스로 공개되어 있어서, 구현체를 직접 하나하나 다 살펴볼 수 있었다(물론 버전에 따라 더 효율적인 방법으로 변경되기도 한다). 그래서 V8에서도 Map의 구현 방법을 세세히 파헤쳐 보았다.
자, 그럼 파헤쳐 보자.
주의 | 아래 적힌 구현의 세부사항들은 최근 Node.js 개발버전(정확하게는 commit 238104c)에 탑재된 V8 8.4의 내용이다. 명세에서 벗어난 내용을 기대하지 말자.
기본 알고리즘
V8에서 Map은 해시테이블로 구현되어있다. 이 글은 해시테이블의 작동방식에 대해 이해하고 있다는 가정하에 작성하였다. 만약 해시테이블에 대해 잘 모른다면 먼저 관련된 내용을 위키 등에서 찾아보고 오기를 바란다.
실무에서 Map을 사용해봤다면 벌써부터 뭔가 모순을 느낄 것이다. 해시테이블은 순서체(iterable)를 위한 그 어떤 순서 정보도 갖고 있지 않는 반면, ES6 명세는 Map을 탐색하는 동안 삽입된 순서를 유지하기 위한 구현을 요구한다. 따라서 "고전적인" 알고리즘은 Map의 구현에 적합하지 않다. 하지만 약간 변형하면 사용할 수 있다.
V8은 Tyler Cloase가 제안한 결정론적 해시 테이블 알고리즘(Deterministic hash tables algorithm)을 사용한다. 다음 의사코드는 이 알고리즘을 이용한 주요 자료구조를 나타낸 것이다.
interface Entry {
key: any;
value: any;
chain: number;
}
interface CloseTable {
hashTable: number[];
dataTable: Entry[];
nextSlot: number;
size: number;
}
여기서 CloseTable 인터페이스는 해시테이블을 나타낸다. 해당 인터페이스는 버킷(역자: 메모리의 데이터 저장 단위)수와 동일한 크기의 hashTable배열을 갖고 있고, 이 배열의 n번째 원소는 n번째 버킷을 의미하며 dataTable 버킷을 가리키는 인덱스를 저장한다. dataTable 배열은 Entry들을 삽입 순서에 따라 저장한다. 각각의 Entry는 chain 프로퍼티를 갖는데, 이는 다음 버킷 체인을 가리키는 정보를 담고 있다. (단방향 링크드 리스트라 보면 된다.)
새로운 항목이 테이블에 삽입될 때마다 dataTable의 인덱스 nextSlot 에 저장되며 새로 저장된 항목이 버킷 체인의 마지막 요소로 업데이트 된다.
해시 테이블에서 항목이 삭제되면, dataTable에서도 삭제된다. 이때 key와 value를 모두 undefined로 설정하므로 항목을 삭제해도 dataTable의 공간을 차지하고 있음을 알 수 있다.
테이블이 항목으로 가득차면(현재 있는 것과 삭제된 것 포함) 더 큰(또는 더 작은) 사이즈로 다시 해싱을 진행해야한다.
이런 방식을 사용하면 Map에서의 순차 실행(iteration)은 dataTable을 통해 반복하는 문제가 된다. 이는 순서체에서 삽입 순서가 구현되는 것을 보장한다. 이를 고려하면 대부분의 JS 엔진 (모두는 아니지만)이 결정론적 해시 테이블을 Map을 구현하는데 사용했을 것이다.
알고리즘 예제
알고리즘이 어떻게 작동하는지에 대한 예제를 살펴보자. CloseTable이 2 버킷 (hashTable.length가 2)이고, 전체 저장 가능 공간이 4 버킷(dataTable.length가 4), 해시테이블의 요소는 다음과 같다고 하자.
// identity hash function를 사용한다 가정,
// i.e. function hashCode(n) { return n; }
table.set(0, 'a'); // => bucket 0 (0 % 2)
table.set(1, 'b'); // => bucket 1 (1 % 2)
table.set(2, 'c'); // => bucket 0 (2 % 2)
이 예시에서 테이블의 내부를 나타내면 다음과 같이 표현할 수 있다.
const tableInternals = {
hashTable: [0, 1],
dataTable: [
{
key: 0,
value: 'a',
chain: 2 // index of <2, 'c'>
},
{
key: 1,
value: 'b',
chain: -1 // -1 means tail entry
},
{
key: 2,
value: 'c',
chain: -1
},
// empty slot
],
nextSlot: 3, // points to the empty slot
size: 3
}
table.delete(0)을 호출하여 항목을 삭제하면, 테이블은 다음과 같이 변한다.
const tableInternals = {
hashTable: [0, 1],
dataTable: [
{
- key: 0,
- value: 'a',
+ key: undefined, // deleted entry
+ value: undefined,
chain: 2
},
{
key: 1,
value: 'b',
chain: -1
},
{
key: 2,
value: 'c',
chain: -1
},
// empty slot
],
nextSlot: 3,
size: 2 // new size
}
만약 항목 2개를 더 추가한다면 해시테이블은 재해싱을 요구한다. 여기에 대해서는 조금 이따가 더 자세히 다뤄보자.
이 알고리즘은 Set에도 적용할 수 있는데, 차이점은 Set의 항목은 value 프로퍼티가 필요없다는 것 정도.
V8의 Map을 구성하는 알고리즘에 대해 알아봤으니, 더 깊게 살펴볼 준비가 되었다.
자세한 구현
V8의 Map 구현은 C++로 작성되어 JS 코드로 보여진다. 메인 부분은 OrderedHahsTable과 OrderedHashMap 클래스에서 정의된다. 이 클래스들이 어떻게 작동하는지는 이미 설명했지만, 코드를 직접 읽고 싶다면 여기, 여기, 그리고 여기에서 찾아볼 수 있다.
V8의 Map 구현에 대한 실용적인 세부 사항을 알아보기 전에 테이블의 저장용량이 정해지는 방법을 먼저 알아보자.
저장용량(Capacity)
V8에서 해시테이블(Map)의 저장용량은 항상 2의 거듭제곱과 같다. 저장 계수(load factor)는 2와 같은 상수로 테이블의 최대 저장용량이 2*number_of_buckets임을 의미한다. 비어있는 Map을 생성하면 내부 해시테이블에 2개의 버킷이 있고, 이 때 테이블은 4개 항목까지 저장할 수 있다.
물론 최대 저장용량에 대한 제한도 있다. 64비트 시스템에서는 $2^{27}$인데, 따라서 Map에는 항목을 약 1,670만개까지만 담을 수 있다. 이런 제한은 Map에 사용되는 heap 표현법에서 비롯된 것이지만 이것도 조금 이따가 다시 다루겠다.
마지막으로 증가/축소 계수(grow/shrink factor)는 2이다. 따라서 Map이 4개의 항목을 저장하면 다음 삽입부터는 기존의 2배 크기의 새로운 해시테이블을 만들어 재해싱한다.
소스코드로 확인해볼 수 있도록 Node.js에 탑재된 V8엔진의 코드를 수정하여 버킷 수를 Map의 buckets 프로퍼티로 드러내었다. 코드는 여기서 볼 수 있다. 다음 스크립트를 Node.js에서 실행해보자.
const map = new Map();
let prevBuckets = 0;
for (let i = 0; i < 100; i++) {
if (prevBuckets !== map.buckets) {
console.log(`size: ${i}, buckets: ${map.buckets}, capacity: ${map.buckets * 2}`);
prevBuckets = map.buckets;
}
map.set({}, {});
}
위의 스크립트는 100개의 항목을 비어있는 Map에 저장한다. 실행 결과는 다음과 같다.
$ ./node /home/jiwon/map-grow-capacity.js
size: 0, buckets: 2, capacity: 4
size: 5, buckets: 4, capacity: 8
size: 9, buckets: 8, capacity: 16
size: 17, buckets: 16, capacity: 32
size: 33, buckets: 32, capacity: 64
size: 65, buckets: 64, capacity: 128
여기서 볼 수 있듯 Map의 저장용량은 다 차면 2의 거듭제곱 꼴로 커진다. 이제 우리의 이론이 확인되었다. 이제 반대로 항목을 삭제하면서 Map이 축소되는 모습을 살펴보자.
const map = new Map();
for (let i = 0; i < 100; i++) {
map.set(i, i);
}
console.log(`initial size: ${map.size}, buckets: ${map.buckets}, capacity: ${map.buckets * 2}`);
let prevBuckets = 0;
for (let i = 0; i < 100; i++) {
map.delete(i);
if (prevBuckets !== map.buckets) {
console.log(`size: ${map.size}, buckets: ${map.buckets}, capacity: ${map.buckets * 2}`);
prevBuckets = map.buckets;
}
}
이 스크립트의 결과는 다음과 같다.
$ ./node /home/puzpuzpuz/map-shrink-capacity.js
initial size: 100, buckets: 64, capacity: 128
size: 99, buckets: 64, capacity: 128
size: 31, buckets: 32, capacity: 64
size: 15, buckets: 16, capacity: 32
size: 7, buckets: 8, capacity: 16
size: 3, buckets: 4, capacity: 8
size: 1, buckets: 2, capacity: 4
Map의 사이즈가 number_of_buckets/2가 되도록 저장용량이 2배씩 축소되는 모습을 볼 수 있다.
해시 함수
지금가지 V8의 Map에서 어떤 해시 함수를 통해 key를 계산하는지 살펴보지 않았지만 이것도 재밌는 주제다. number-like 데이터(Smis, heap number, BigInt 등 비슷한 데이터)는 충돌 확률이 낮다고 잘 알려진 해시함수를 이용한다. 문자열과 유사한 값(string, symbol)의 경우 문자열의 내용을 기반으로 해시 코드를 계산한 다음 내부 헤더에 캐싱한다. 마지막으로 객체의 경우 V8은 난수를 기반으로 해시코드를 계산하고 내부 헤더에 캐싱한다.
시간 복잡도
set이나 delete와 같은 대부분의 Map 연산들은 조회 작업이 필요하다. "고전적인" 해시테이블에서 조회 횟수는 $O(1)$의 시간 복잡도를 갖는다.
최악의 경우를 생각해보자. 테이블에 저장할 수 있는 용량이 N개면 N개의 항목이 있고(가득 참) 모든 항목이 하나의 버킷에 저장되어 있으며 찾는 항목이 제일 마지막 원소에 있다고 하자. 이런 시나리오에서, 조회는 체인에서 N개의 원소들을 조회 해야한다.
반면 가능한 가장 좋은 시나리오는 테이블이 가득 찼지만 모든 버킷이 2개의 항목만 갖는 경우로, 2번만 조회해서 원하는 값을 조회할 수 있다.
해시 테이블의 개별 작업은 비용이 낮지만 재해싱은 그렇지 않다는 것은 잘 알려진 사실이다. 재해싱은 $O(N)$의 시간 복잡도를 가지며 힙에 새 해시 테이블을 할당해야 한다. 또한 필요한 경우 삽입과 삭제 작업 중 재해싱이 이루어진다. 그렇기 때문에 map.set() 호출은 우리의 예상보다 더 많은 비용을 요구할 수 있다. 그렇지만 운 좋게도 재해싱은 비교적 드물게 일어난다.
메모리 풋 프린트
물론 기본 해시 테이블은 어떻게든 백업 저장소(backing store)에 저장되어야 한다. 여기서 재밌는 점은 전체 테이블(물론 Map도)은 고정된 길이의 단일 배열로 저장된다는 것이다. 배열의 형태는 다음 그림을 살펴보자.
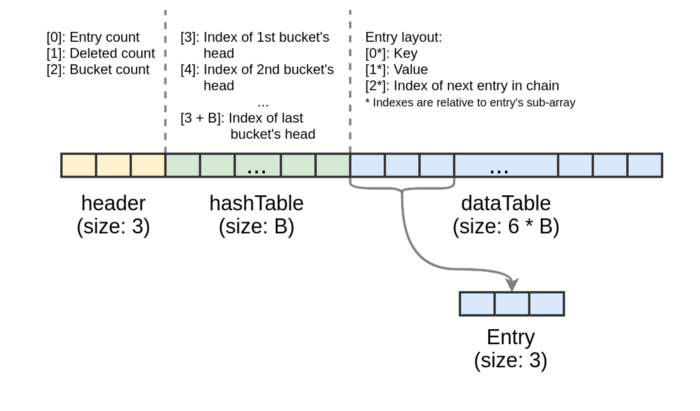
백업 저장소 배열의 특정 조각은 헤더(버킷 수 또는 삭제된 항목 수와 같은 필수 정보 포함), 버킷 및 항목에 해당한다. 버킷 체인의 각 항목은 백업 저장소 배열에서 세 칸(key, value, 체인의 다음 항목에 대한 포인터)을 차지한다.
배열의 크기는 N이 테이블의 저장용량(capacity)이라 했을 때 어림잡아 N * 3.5 정도로 계산할 수 있다. 이렇게 계산되는 이유는 메모리 풋 프린트 때문인데, 64비트 시스템이고 V8의 포인터 압축 기능을 비활성화한 환경을 가정하자. 이런 환경에서, 배열 각각의 원소는 8바이트를 요구하고, 저장용량이 $2^{20}$(~1M)인 Map은 대략 29MB의 힙 메모리를 차지한다.
요약
후. 여기까지 읽느라 수고하셨다. 다음은 우리가 이 글을 통해 V8의 Map에 대해 알게된 짧은 리스트다.
- V8은 Map을 구현하는데 결정론적(deterministic) 해시 테이블 알고리즘을 사용하며, 다른 JS 엔진들도 비슷하다.
- Map은 C++로 구현되어 JS API로 제공된다.
- 고전적인 해시 맵에서 Map 연산을 위한 조회는 $O(1)$이고 재해싱은 $O(N)$이다.
- 64비트 시스템, 포인터 압축을 비활성화 환경에서 1,000,000개의 항목이 저장된 Map은 29MB 정도의 힙 메모리를 차지한다.
- 이 글에서 설명한 대부분의 내용은 Set에도 적용할 수 있다.
이만 글을 마친다. 다음 V8 Deep Dive에 대한 아이디어가 있다면 내게공유 해주길 바란다.